深入浅出NodeJS
很厉害的一本书,从其中几个模块的实现和解决思路中学到了很多东西;http 协议方面的东西也在这本书上面恶补了一番,很充实。终于吃完了,吃的很饱撒花哗啦啦
模块机制
CommonJS 规范
模块引用
|
CommonJS 规范中存在 require() 方法,接受模块标识,以此引入一个模块的 API 到当前的上下文
模块定义
|
在模块中,上下文提供 require() 方法引入外部模块,提供 exports 对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。模块存在一个 module 对象,代表模块本身,而 exports 对象是 module 的属性。在 Node 中,一个文件就是一个模块
Node 的模块实现
Node 中引入模块经历的步骤如下:路径分析 => 文件定位 => 编译执行。其中,核心模块部分在 Node 源代码编译过程中,编译进了二进制执行文件,在 Node 进程启动时直接加载进内存中,只需要路径分析,并且在路径分析中优先判断
- 优先从缓存加载
- 核心模块、路径形式的文件模块、自定义模块
- Node 提供的模块属于核心模块
- 用户编写的模块属于文件模块。以
.、..、/开始的标识符,被当做文件模块处理 - 自定义模块指的是非核心模块,也不是路径形式的标识符。可能是一个文件或者包的形式。沿路径向上逐级递归,直到根目录下的 node_module 目录为止,查找最费时
- 文件定位,按 .js、.json、.node 的次序补足扩展名,依次尝试
- 目录分析和包,Node 在自定义模块目录下查找 package.json,通过
JSON.parse解析,并取出 main 属性制定的文件名进行定位。如果没有 package.json,将依次查找 index.js、index.json、index.node - 模块编译 TODO
包与NPM
NPM 是 CommonJS 包规范理论的实践。符合 CommonJS 规范的包目录包含如下文件:
- package.json:包描述文件
- bin:用于存放可执行二进制文件的目录
- lib:用于存放 Javascript 代码的目录
- doc:用于存放文档的目录
- test:用于存放单元测试用例的代码
安装依赖包
全局模式安装,是将一个包安装为全局可用的可执行命令。它根据包描述文件中的 bin 字段配置,将实际脚本链接到 Node 可执行文件相同的可执行路径下
全局安装的模块包都被安装进一个统一的目录下,通过如下方式推算出来
path.resolve(process.execPath, '..', '..', 'lib', 'node_module');即 Node 可执行文件的位置是
/usr/local/bin/node,则模块目录为/usr/local/lib/node_module本地安装,只需要为 NPM 指明 package.json 文件所在位置即可,可以是一个包含 package.json 的存档文件,也可以是一个 URL 地址,也可以是一个目录下 package.json 文件的目录位置
npm install <tarball file>npm install <tarball url>npm install <folder>从非官方源安装
npm install undescore --registry=http://registry.url使用过程都使用镜像源安装
npm config set registry http://registry.url
异步I/O
Node 的异步I/O
事件循环
Node 进程启动时,会启动一个循环,每执行一次循环称为 Tick。每个 Tick 的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程
事件循环是一个典型的生产者 / 消费者模型。异步 I/O、网络请求等则是事件的生产者,为 Node 提供不同类型的事件,这些事件被传递到对应的观察者,事件循环则从观察者那里取出事件并做处理
请求对象
从 Javascript 调用 Node 的核心模块,核心模块调用 C++ 内建模块,内建模块通过 libuv 进行系统调用,这是 Node 里经典的调用方式。这里 libuv 作为封装层,有两个平台的实现。调用过程中会创建一个请求对象并推入线程池中等待执行。不管当前的 I/O 操作是否阻塞 I/O,都不会影响到 Javascript 线程的后续执行
执行回调
组装好请求对象、送入 I/O 线程池等待执行,实际上完成了异步 I/O 的第一部分,回调通知是第二部分。在线程池中的 I/O 操作调用完毕之后,会储存获取的结果然后通知 IOCP,告知当前对象操作已经完成
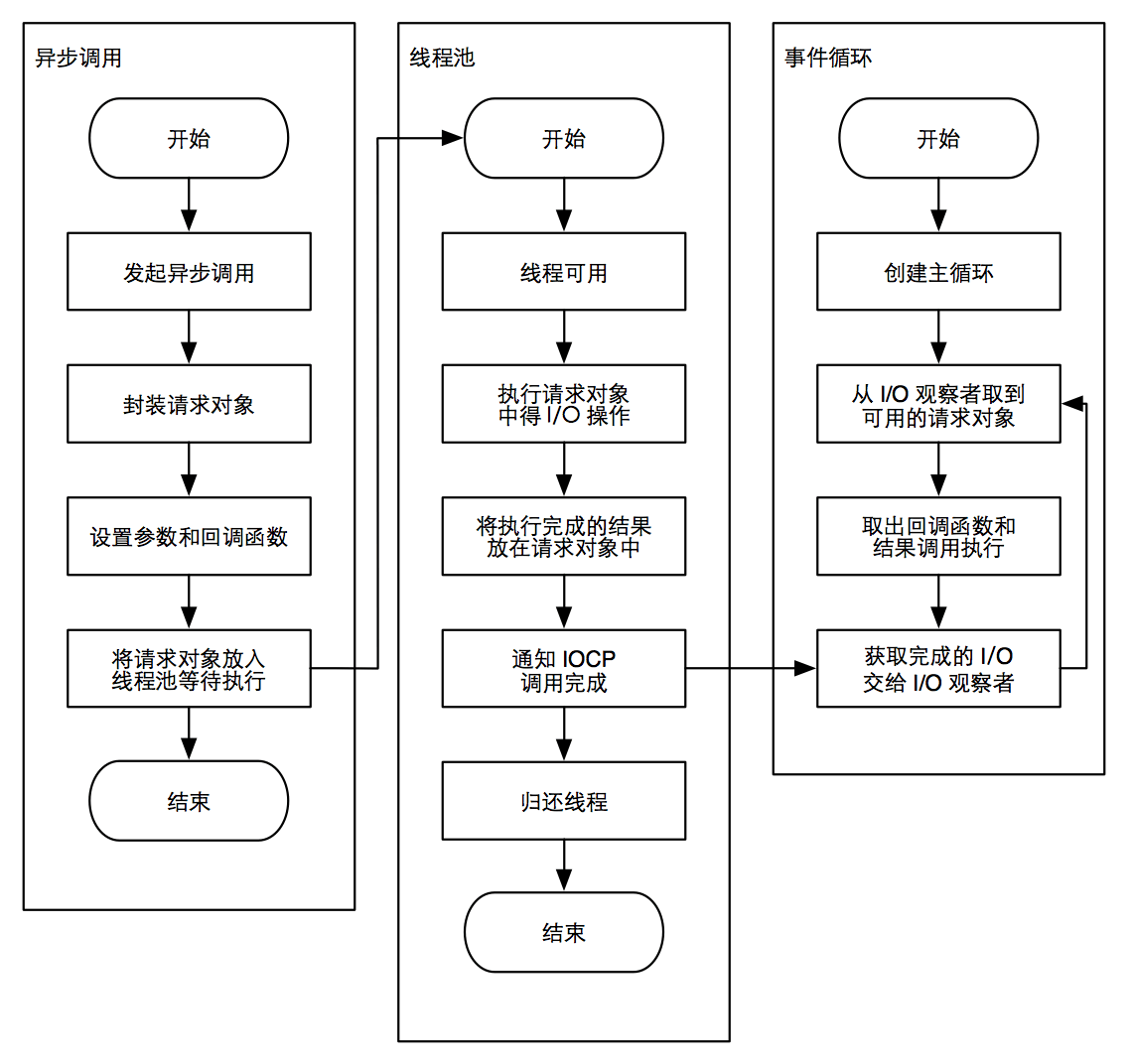
事件循环、观察者、请求对象、I/O 线程池这四者共同构成了 Node 异步 I/O 模型的基本要素
Windows 下主要通过 IOCP 来向系统内核发送 I/O 调用和从内核获取已完成的 I/O 操作,配以事件循环,以此完成异步 I/O 的过程。在 Linux 下通过 epoll 实现这个过程,FreeBSD 下通过 kqueue 实现,Solaris 下通过 Event ports 实现。不同的是线程池在 Windows 下由内核(IOCP)直接提供,*nix 系列下由 libuv 自行实现
小结
在 Node 中,除了 Javascript 是单线程外,Node 自身是多线程,只是 I/O 线程使用的 CPU 较少。另一个观点是,除了用户代码无法并行执行外,所有的 I/O 则是并行起来的
非 I/O 的异步 API
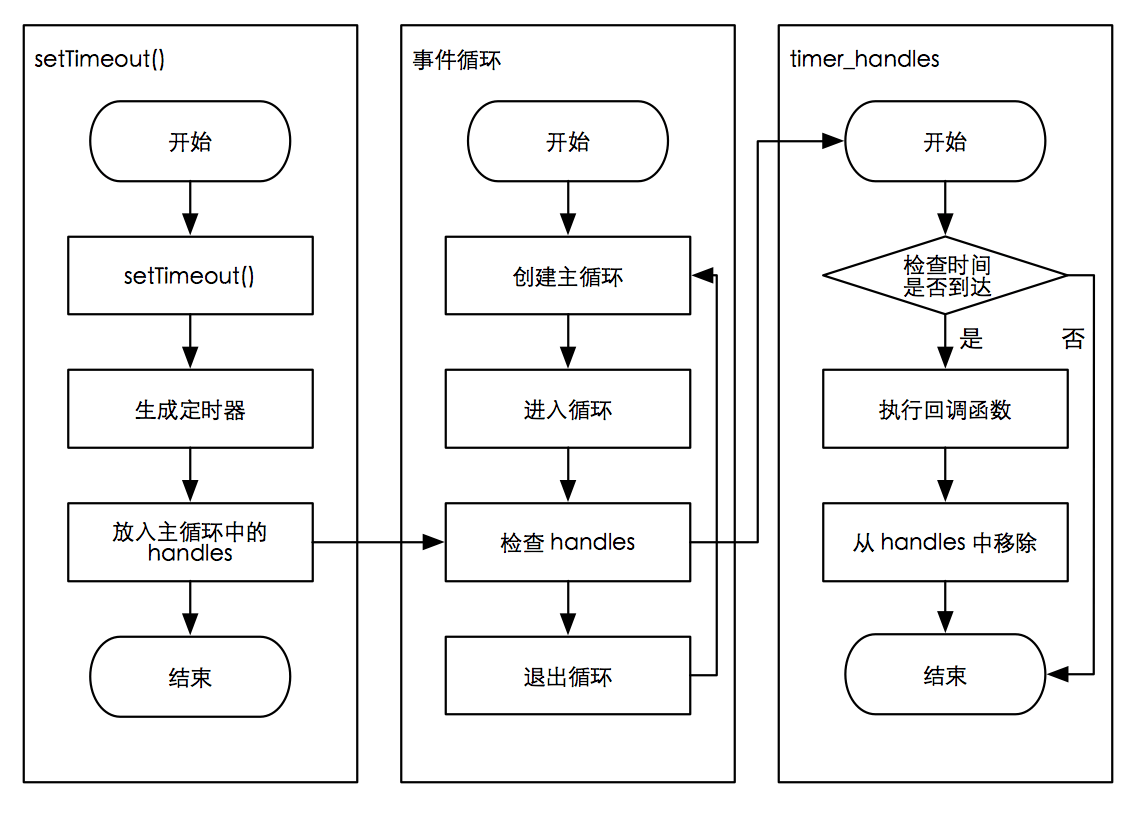
定时器
setTimeout() 和 setInterval() 与浏览器中的 API 是一致的。它们的实现原理与异步 I/O 类似,只是不需要 I/O 线程池的参与。创建的计时器会被插入到定时器观察者内部的一个红黑树中,每次 Tick 执行时,会从该红黑树中迭代取出定时器对象,检查是否超过定时时间,如果超过,就形成一个事件,它的回调函数将会立即执行
定时器的问题并不精确,例如通过计时器设定一个任务在10毫秒后执行,但在9毫秒后,有一个任务占用了5毫秒的 CPU 时间片,再次轮到定时器执行时,时间就已经过期4毫秒了
process.nextTick()
采用定时器需要动用红黑树,创建定时器对象和迭代等操作。相比执行,process.nextTick() 方法的操作相对较为轻量。每次调用 process.nextTick() 方法,只会将回调函数放入队列中,在下一轮 Tick 时取出执行。定时器中采用红黑树的操作时间复杂度为 O(lg(n)),nextTick() 的时间复杂度为 O(1)
setImmediate()
process.nextTick() 中的回调函数执行的优先级高于 setImmediate(),原因在于事件循环对观察者的检查有先后顺序。process.nextTick() 属于 idle 观察者,setImmediate() 属于 check 观察者。在每一轮循环检查中,idle 观察者优先于 I/O 观察者,I/O 观察者优先于 check 观察者
事件驱动与高性能服务器
几种经典的服务器模型
- 同步式。对于同步式的服务,一次只能主力一个请求,并且其余请求都处于等待状态
- 每进程/每请求。为每个请求启动一个进程,这样可以处理多个请求,但是它不具备扩展性,因为系统资源只有那么多
- 每线程/每请求。为每个请求启动一个线程来处理。尽管线程比进程轻量,但是每个线程都占用一定内存,大并发请求来时,内存会很快耗光
Node 通过事件驱动的方式处理请求,无需为每一个请求创建额外的对应线程,可以省掉创建线程和销毁线程的开销
异步编程
异步编程难点
- 异常处理
- 函数嵌套过深
- 阻塞代码
- 多线程编程
- 异步转同步
异步解决方案
- 事件发布 / 订阅模式
- Promise / Deferred 模式
- 流程控制库
时间发布/订阅模式
订阅事件是一个高阶函数的应用。事件发布/订阅模式可以实现一个事件与多个回调函数的关联,这些回调函数又称为事件侦听器。从另一个角度看,事件侦听器模式也是一种钩子机制,利用钩子导出内部数据或状态给外部的调用者
Node 对事件发布/订阅的机制做了一些额外的处理
- 如果对一个事件添加超过 10 个侦听器,将会得到一条警告。可以调用
emmiter.setMaxListeners(0)去除限制 - EventEmmiter 对象对 error 事件进行了特殊对待。如果运行期间的错误触发了 error 事件,EventEmitter 会检查是否由对 error 事件添加过侦听器。如果有,则将错误交给该侦听器处理,否则作为异常抛出。如果外部没有捕获这个异常,将会引起线程退出
通过继承 events 模块可实现事件机制
|
多异步之间的协作方案
由于多个异步场景中回调函数的执行并不能保证顺序,且回调函数之间相互没有任何交集,因此需要借助一个第三方函数和第三方变量来处理异步写作的结果。通常,我们把这个用于检测次数的变量叫做哨兵变量
|
通过 EventProxy 解决异步协作
|
Promise / Deferred 模式
Promise/A
Promise/A 对单个异步操作的抽象定义如下
- Promise 只会出于三种状态中的一种:未完成态、完成态或失败态
- Promise 的状态只会出现从未完成态向完成态或失败态转化,不能逆转。完成态和失败态不能相互转化
- Promise 的状态一旦转化,将不能被改变
Promise/A 提议在 API 的定义中,一个 Promise 对象只要具备 then() 方法即可,有如下要求
- 接受完成态、错误态的回调函数。在操作完成或者出现错误时,将会调用对应方法
- 可选地支持 progress 事件回调作为第三个方法
- then() 方法只接受 function dioxide。其余对象将被忽略
- then() 方法继续放回 Promise 对象,以实现链式调用
|
|
then() 方法将回调函数存放起来。为了完成整个流程,还需要执行这些回调函数的地方,实现这些功能的对象称为 Deferred,即延迟对象
|
封装业务代码
|
典型响应对象的调用
|
与事件发布/订阅模式相比,Promise/Deferred 模式的 API 接口和抽象模型都十分简洁。它将业务中不可变的部分封装在了 Deferred 中,将可变的部分交给了 Promise。对于不同场景需要封装对应的 Deferred 部分
多异步协作可通过哨兵变量和 result 数组实现
流程控制库
尾触发与 Next
需要手工调用才能持续执行后续调用的方法属于尾触发,常见的关键词是 next。目前应用最多的 diff 是 Connect 的中间件,在处理网络请求时,可以像面向切面编程一样进行过滤,验证,日志等功能,而不与具体业务逻辑产生关联,以致产生耦合var app = connect();app.use(connect.staticCache());app.use(connect.static(__dirname + '/public'));app.use(connect.query());app.use(connect.bodyParse());app.listen(3001);function(req, res, next) {//中间件}async
async.series([function(callback) {fs.readFile('file1.txt', 'utf-8', callback);},function(callback) {fs.readFile('file2.txt', 'utf-8', callback);}], function(err, results) {// result => [file1.txt, file2.txt]s});Step
// 串行依次执行Step(function readFile1() {fs.readFile('file1.txt', 'utf-8', this);},function readFile2() {fs.readFile('file2.txt', 'utf-8', this);},function done(err, content) {console.log(content);})wind
var Wind = require('wind');var Task = Wind.Async.Task;var readFile = function(file, encoding) {return Task.create(function(t) {fs.readFile(file, encoding, function(err, file) {if(t.err) {t.complete('failure', err);} else {t.complete('success', file)}})});}var series = eval(Wind.compile('async', function() {var file1 = $await(readFileAsync('file1.txt', 'utf-8'));console.log(file1);var file2 = $await(readFileAsync('file2.txt', 'utf-8'));console.log(file2);try {var file1 = $await(readFileAsync('file3.txt', 'utf-8'));} catch(err) {console.log(err)}}));
异步并发控制
bagpipe 的解决方案
- 通过一个队列来控制并发量
- 如果当前活跃的异步调用量小于限量值,从队列中取出执行
- 如果活跃调用达到限量值,调用暂时存放在队列中
每个异步调用结束时,从队列中取出新的异步调用执行
var Bagpipe = require('bagpipe');var bagpipe = new Bagpipe(10);for(var i=0; i<100; i++) {bagpipe.push(async, function() {// 异步回调执行});}bagpipe.on('full', function(length) {console.warn('full queue: ' + length);});
async
async.parallelLimit([function(callback) {fs.readFile('file1.txt', 'utf-8', callback);},function(callback) {fs.readFile('file2.txt', 'utf-8', callback);}], 1, function() {// TODO});var q = async.queue(function(file, callback) {fs.readFile(file, 'utf-8', callback);}, 2);q.drain = function() {// done};fs.readdirSync('.').forEach(function(file) {q.push(file, function(file) {// TODO});});
内存控制
V8的垃圾回收机制与内存限制
在 V8 中,所有的 Javascript 对象都是用过堆来进行分配的。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到堆的大小超过 V8 的限制。V8 限制堆的大小,原因在于垃圾回收中会引起 Javascript 线程暂停执行,而糟糕情况下造成的时间花销将影响应用性能和响应能力
V8 中,将内存分为新生代和老生代。新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或者常驻内存的对象
分代的基础上,新生代中的对象主要通过 Scavenge 算法进行垃圾回收。在 Scavenge 的具体实现中,主要采用了 Cheney 算法。简单表述,在垃圾回收的过程中,就是通过将存活对象在两个 semispace 空间中进行复制,属于典型的牺牲空间换取时间的算法
在一定条件下,需将存活周期长的对象移动到老生代中,也就是完成对象晋升。判断条件为对象是否经历过 Scavenge 回收和 To 空间的内存占用比超过限制
老生代空间中得对象接受新的回收算法处理,主要采用 Mark-Sweep 和 Mark-Compact 相结合的方式。Mark-Sweep 是标记清楚的意思,分为标记和清理清除两个阶段;Mark-Compact 解决 Mark-Sweep 的内存碎片问题,将存活的对象往一端移动,完成后直接清理掉边界外的内存
为了避免出现 Javascript 应用逻辑与垃圾回收期看到不一致的情况,垃圾回收的3种基本算法都需将应用逻辑暂停下来,待执行完垃圾回收之后在回复执行应用逻辑,这种行为被称为“全停顿”(stop-the-world)。全堆垃圾回收的标记、清理、整理等动作造成的停顿比较可怕,因此采用增量标记(incremental marking),垃圾回收与应用逻辑交替执行直到标记阶段完成
高效使用内存
作用域
在 Javascript 中能形成作用域的有函数调用、with 和全局作用域。作用域中声明的局部变量分配在该作用域上,随作用域的销毁而销毁
如果变量是全局变量(不通过 var 声明或定义在 global 上),由于全局作用域需要直到进程退出才能释放,此时将导致引用的对象常驻内存(常驻在老生代中)。如果需要释放常驻内存的对象,可以通过 delete 操作来删除引用关系,或者将变量重新赋值,让旧的对象脱离引用关系,在接下来的老生代内存清除和整理的过程中,会被回收释放
闭包
实现外部作用域访问内部作用域中的变量的方法叫做闭包。一旦有变量引用内部作用域的变量,原始的作用域不会得到释放
内存指标
查看进程的内存占用
|
rss 是 resident set size 的缩写,即进程的常驻内存部分。进程的内存总共有几部分,一部分是 rss,其余部分在交换区(swap)或者文件系统(filesystem)中
除了 rss 外,heapTotal 和 heapUsed 对应的是 V8 的堆内存信息,heapTotal 是堆中总共申请的内存量,heapUsed 表示目前堆中使用中的内存量。三个值的单位都是字节
查看系统内存占用
|
堆外内存
process.memoryUsage() 的结果可知,堆中的内存用量总是小于进程的常驻内存用量,意味着 Node 中的内存使用并非都是通过 V8 进行分配的,我们将那些不是通过 V8 分配的内存称为堆外内存
Buffer 对象不同于其他对象,它不经过 V8 的内存分配机制,所以不会有堆内存的大小限制
小结
Node 的内存构成主要是通过 V8 进行分配的部分和 Node 自行分配的部分,受 V8 的垃圾回收限制的主要是 V8 的堆内存
内存泄露
实质是应当回收的对象出现意外而没有被回收,变成了常驻在老生代中的对象。可能的原因有:缓存、队列消费不及时、作用域未释放
缓存限制机制
由于模块的缓存机制,模块都是常驻老生代的。在设计模块时,要十分小心内存泄露的出现,避免调用导出方法时不停增加内存的占用。当不可避免时可添加相关接口供使用者释放内存
缓存的解法方案
大量使用缓存的一个解决方法是使用进程外的缓存,进程自身不储存状态。外部的缓存软件有着良好的缓存过期淘汰策略以及自有的内存管理,不影响 Node 进程的性能,在 Node 中可解决以下问题
- 将缓存转移到外部,减少常驻内存的对象的数量,让垃圾回收更加高效
- 进程之间可以共享缓存
关注队列状态
队列在消费者-生产者模式中经常充当中间产物,当消费速度低于生成速度,将会形成堆积,出现内存泄露。表面的解决方案是换用消费速度更高的技术;深度的解决方案是监控队列的长度,一旦堆积,应通过监控系统产生报警通知相关人员,或者为任意异步调用添加超时机制
内存泄露排查
定位 Node 应用的内存泄露的常用工具如下:
- v8-profiler
- node-heapdump
- dtrace
- node-memwatch
理解 Buffer
Buffer 结构
模块结构
Buffer 是一个典型的 Javascript 与 C++ 结合的模块,它将性能相关部分用 C++ 实现,将非性能相关的部分用 Javascript 实现
Buffer 对象
Buffer 对象类似数组,它的元素为16进制的两位数,即0到255的数值。其中中文字符在 UTF-8 编码下占用3个元素,字母和半角标点符号占用一个元素
|
给元素的赋值如果小于0,就将该值逐次加256,直到得到一个0到255之间的整数。如果得到的数值大于256,就逐次减256。如果是小数,舍弃小数部分,只保留整数部分
Buffer 内存分配
Node 使用 slab 分配机制使用申请来的内存。当进行小而频繁的 Buffer 操作时,采用 slab 的机制进行预先申请和事后分配,使得 Javscript 到操作系统之间不必有过多的内存申请方面的系统调用。对于大块的 Buffer 而言,则直接使用 C++ 层面提供的内存,而无需细腻的分配操作
Buffer 的转换
Buffer 对象与字符串之间相互转换,目前支持的字符串编码类型如下:
- ASCII
- UTF-8
- UTF-16LE/UCS-2
- Base64
- Binary
- Hex
字符串转 Buffer
|
通过构造函数转换的 Buffer 对象,存储的只能是一种编码类型,encoding 参数不传递时,默认按 UTF-8 编码进行转码和存储。调用 write() 方法可以在一个 Buffer 对象中存储不同编码类型的字符串编码的至,但需要小心每种编码所用的字节长度不同,将 Buffer 对象反转成字符串时需谨慎处理
Buffer 转字符串
|
buffer 不支持的编码类型
Buffer 对象提供 isEncoding() 函数判断编码是否支持转换
|
可借助 iconv-lite 或 iconv 支持更多编码类型。前者采用纯 Javascript 实现,更轻量,无需编译和处理环境依赖直接使用;后者通过 C++ 调用 libiconv 库实现。性能方面由于转码都是耗用 CPU,在 V8 下少了 C++ 到 Javascript 层次的转换,纯 Javascript 的性能比 C++ 实现更好
|
iconv-lite 和 iconv 对无法转换的内容进行降级处理时的方案不同
Buffer 的拼接
|
data 事件中获取的 chunk 对象即是 Buffer 对象。因此,拼接 data 的过程中,相当于隐藏调用了chunk.toString()(默认以UTF-8编码)。如果存在宽字节编码,则可能出现乱码
可以通过为可读流设置编码,使 data 事件中传递的不再是一个 Buffer 对象,而是编码后的字符串.
|
事实上,调用 setEncoding() 时,可读流对象在内部设置了一个 decoder 对象。每次都通过该 decoder 对象进行 Buffer 到字符串的解码,然后传递给调用者。decoder 对象来自于 string_decoder 模块 StringDecoder 的实例对象,能根据编码类型处理可读流的字节长度问题。但它目前只能处理 UTF-8、 Base64 和 UCS-2/UTF-16LE 这三种编码
可通过 iconv-lite 一类的模块,将可读流获取的 Buffer 对象拼接后做转换,解决转码问题
Buffer 与性能
字符串一旦在网络中传输,都需要转换为 Buffer,以进行二进制数据传输。通过预先转换静态内容为 Buffer 对象,可以有效地减少 CPU 的重复使用,节省服务器资源
Buffer 的使用除了与字符串的转换有性能耗损外,在文件读取时,还有一个 highWaterMark 设置对性能的影响至关重要。highWaterMark 限制每次读取的长度,对 Buffer 内存的分配和使用有一定影响,设置过小可能导致系统调用次数过多。
文件流读取基于 Buffer 分配,Buffer 则基于 SlowBuffer 分配
网络编程
Node 提供了 net、 dgram、 http、 https 这4个模块,分别用于处理 TCP、 UDP、 HTTP、 HTTPS
构建 TCP 服务
TCP 全名为传输控制协议,在 OSI 模型(由七层组成,分别为物理层、数据链路层、网络层、传输层、会话层、表示层、应用层)中属于传输层协议。许多应用层协议基于 TCP 构建,典型的是 HTTP、 SMTP、 IMAP 等协议
TCP 是面向连接的协议,其显著的特征是在传输之前需要3次握手形成会话。在创建会话的过程中,服务器端和客户端分别提供一个套接字,这两个套接字共同形成一个连接。服务器端和客户端则通过套接字实现两者之间连接的操作
服务器事件
listening:在调用 server.listen() 绑定端口或者 Domain Socket 后触发,简洁写法为
server.listen(port, listeneringListener)connection:每个客户端套接字连接到服务器端时触发,简介写法为通过 net.createServer(),最后一个参数传递
- close:当服务器关闭时触发,在调用 server.close() 后,服务器将停止接受新的套接字连接,但保存当前存在的连接,等待所有连接都断开后,会触发该事件
- error:当服务器发生异常时,将会触发该事件。比如侦听一个使用中的端口,将会触发一个异常。如果不侦听 error 事件,服务器将会抛出异常
连接事件
服务器可以通过与多个客户端保持连接,对于每个连接而言是典型的可写可读 Stream 对象。Stream 可用户与服务器和客户端之间的通信,它具有如下自定义事件
- data:当一段调用 write() 发送数据时,另一端会触发 data 事件
- end:当连接中的任意一端发送了 FIN 数据时,触发该事件
- connect:用于客户端,当套接字与服务器端连接成功时被触发
- drain:当任意一端调用 write() 发送数据时,当前这端会触发该事件
- error:异常发生时候触发
- close:当套接字完全关闭时触发
- timeout:当一定时间后连接不再活跃时触发,通知用户当前该连接已经被闲置
TCP 针对网络中的小数据包有一定的优化策略:Nagle 算法。要求缓冲区的文件达到一定数量或者一定时间后才将其发出,所以数据包会被 Nagle 算法合并,以此优化网络,但数据可能被延迟发送。Node 中 TCP 默认使用 Nagle 算法,可以使用socket.setNoDelay(true)取消。尽管如此,并不意味着每次 write() 都会触发一次 data 事件,另一端可能将会接收到多个小数据包合并,然后只触发一次 data 事件
构建 UDP 服务
UDP 又称用户数据包协议,与 TCP 一样属于网络传输层。与 TCP 最大不同是 UDP 不是面向连接的。TCP 中连接一旦建立,所有的会话都会基于连接完成,客户端如果要与另一个 TCP 服务通信,需要另外创建一个套接字来完成连接。但在 UDP 中,一个套接字可以与多个 UDP 服务通信,它提供面向事务的简单不可靠信息传输服务,在网络差的情况下丢包严重,但由于它无需连接,资源消耗低,处理快速且灵活,所以常用于偶尔丢包也不会产生重大影响的场景,如音频、视频等。DNS 服务是基于 UDP 实现的
|
|
UDP 套接字事件
UDP 套接字只是一个 EventEmitter 的实例,而非 Stream 的实例
- message:当 UDP 套接字侦听网卡端口后,接受到消息时触发该事件,触发携带的数据为消息 Buffer 对象和一个远程地址信息
- listening:当 UDP 套接字开始侦听时触发事件
- close:调用 close() 方法时触发该事件,并不再触发 message 事件
- error:当异常发生时触发该事件,如果不侦听,异常将直接抛出
构建 HTTP 服务
TCP 和 UDP 都属于网络传输层协议,如果要构造高效的网络应用,应该从传输层进行着手。HTTP 构建与 TCP 之上
HTTP 报文
|
第一部分是 TCP 的3次握手的过程;第二部分是完成握手之后,客户端向服务器端发送请求报文;第三部分是服务器端完成处理后,向客户端发送响应内容,包括响应头和响应体;最后是结束会话的信息
HTTP 是基于请求响应式的,虽然基于 TCP 会话,但本身却并无会话的特点
http 模块
HTTP 服务与 TCP 服务模型由区别的地方在于,在开启 keepalive 后,一个 TCP 服务可以用于多次请求和响应。TCP 服务以 connection 为单位进行服务,HTTP 服务以 request 为单位进行服务。http 模块即是将 connection 到 request 的过程进行了封装
除此之外,http 模块将连接所用套接字的读写抽象为 ServerRequest 和 ServerResponse 对象,分别对应请求和响应操作
HTTP 请求
对于 TCP 连接的读操作,http 模块将其封装为 ServerRequest 对象。报文头被解析防止在 req.headers 属性上,报文体部分则抽象为一个只读流对象
HTTP 响应
封装了对底层连接的写操作,可以将其看做一个可写的流对象。报文头信息通过setHeader()和writeHead()写入,报文体通过调用res.write()和res.end()方法实现。无论服务器端在处理业务逻辑时是否发生异常,务必在结束时调用res.end()结束请求,否则客户端将会一直处于等待状态。也可以通过延迟 res.end() 的方法实现客户端与服务器端的长连接,但结束时务必关闭连接
HTTP 服务的事件
- connection 事件:在开始 HTTP 请求和响应之前,客户端与服务器端需要建立底层的 TCP 连接,这个连接可能因为开启了 keep-alive,可以在多次请求响应之间使用;当这个连接建立时,服务器触发一次 connection 事件
- request 事件:建立 TCP 连接后,http 模块底层将在数据流中抽象出 HTTP 请求和 HTTP 响应,当请求数据发送到服务器端,在解析出 HTTP 请求头后,将会触发该事件;在 res.end() 之后,TCP 连接可能将用于下一次响应请求
- close 事件:与 TCP 服务器的行为一致,调用 server.close() 方法停止接受新的连接,当已有的连接都断开时,触发该事件;可以给 server.close() 传递一个回调函数来快速注册该事件
- checkContinue 事件:某些客户端在发送较大的数据时,并不会将数据直接发送,而是先发送一个头部带
Except: 100-continue的请求到服务器,服务器触发该事件;如果没有为服务器监听该事件,服务器将会自动响应客户端100 Continue的状态码,表示接受数据上传;否则响应400 Bad Request拒绝客户端发送数据。需要注意的是,该事件不会触发 request 事件,两个事件互斥。当客户端收到100 Continue后重新发起请求时,才会触发 request 事件
HTTP 客户端
|
options 参数决定了 HTTP 请求头的内容
- host:服务器的域名或 IP 地址,默认为 localhost
- hostname:服务器名称
- port:服务器端口,默认为 80
- localAddress:建立网络连接的本地网卡
- socketPath:Domain 套接字路径
- method:HTTP 请求方法,默认为 GET
- path:请求路径,默认为 /
- headers:请求头对象
- auth:Basic 认证,这个值将被计算成请求头中的 Authorization 部分
HTTP 代理
http 提供的 CLientRequest 对象也是基于 TCP 层实现,在 keepalive 的情况下,一个底层会话连接可以多次用于请求。为了重用 TCP 链接,http 模块包含一个默认的客户端代理对象 http.globalAgent。它对每个服务器端(host+port)创建的连接进行了管理,默认情况下,通过 ClientRequest 对象对同一个服务器发情的 HTTP 请求最多可以创建五个连接。它实质上是一个连接池
服务器通过 ClientRequest 调用网络中其它 HTTP 服务,需要关注代理对象对网络请求的限制。可通过 options 中的 agent 选项配置。默认情况下采用全局代理对象,默认连接数限制为5
|
HTTP 客户端事件
- response:与服务器端的 request 事件对应的客户端在请求发出后得到服务器端响应时触发
- socket:当底层连接池中建立的连接分配给当前请求对象时触发
- connect:当客户端向服务器端发情 CONNECT 请求时,如果服务器端响应 200 状态吗,客户端将会触发事件
- upgrade:客户端向服务器端发送 Upgrade 请求时,如果服务器端响应了 101 Switching Protocols 状态,客户端将会触发该事件
- continue:客户端向服务器端发起 Expect: 100-continue 头信息,以试图发送较大数据量,如果服务器端响应 100 Continue 状态,客户端触发该事件
构建 WebSocket 服务
WebSocket 协议主要分为握手和数据传输两部分。相比 HTTP,WebSocket 更接近于传输层协议,它并没有在 HTTP 的基础上模拟服务器端的推送,而是在 TCP 上定义独立的协议。但 WebSocket 的握手部分是由 HTTP 完成的
WebSocket 握手
客户端请求报文
|
- Upgrade, Connect:表示请求服务器端升级协议为 WebSocket
- Set-WebSocket-Key:随机生成的 Base64 编码的字符串,用于安全校验
- Set-WebSocket-Protocol:指定子协议
- Set-WebSocket-Version:指定版本号
服务器端响应报文
|
WebSocket 数据传输
在握手顺利完成后,当前连接将不再进行 HTTP 的交互,而是开始 WebSocket 的数据帧协议,实现客户端与服务器端的数据交换
WebSocket 数据帧的定义,每八位为一列,也即1个字节
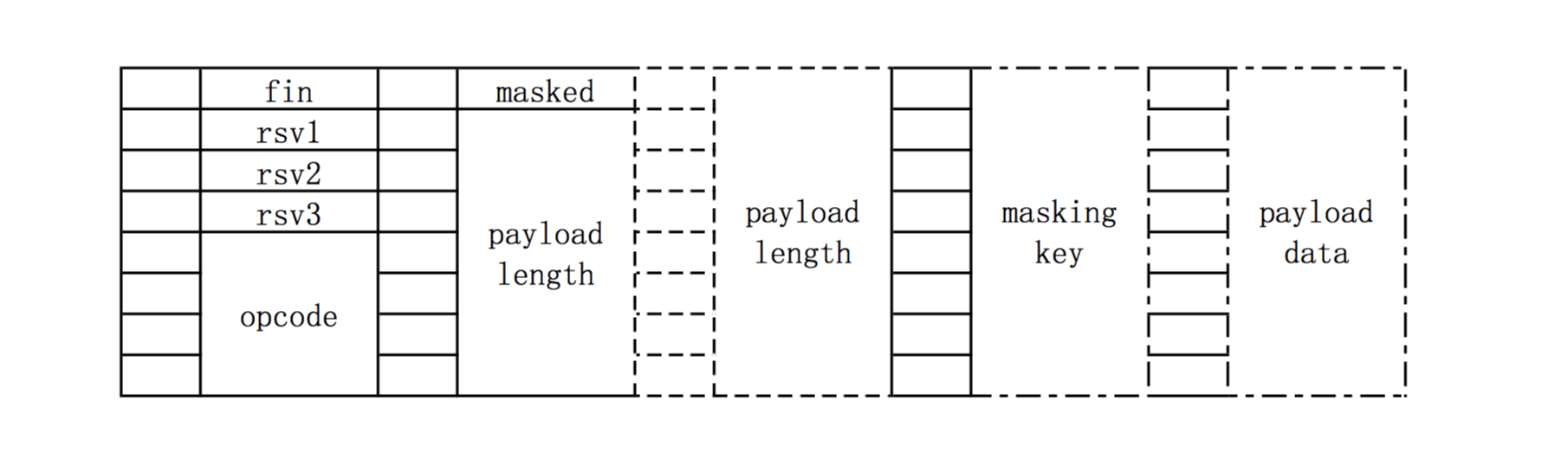
- fin:如果这个数据帧是最后一帧,这个 fin 位为1,其余情况为0.当一个数据没有被分为多帧时,它既是第一帧也是最后一帧
- rsv1、 rsv2、 rsv3:各为1位长,3个标识用于扩展,当已协商的扩展时,这些值可能为1,其余情况为0
- opcode:长为4位的操作码,可以用来表示0到15的值,用于解释当前数据帧。0表示附加数据帧,1表示文本数据帧,2表示二进制数据帧,8表示发送一个连接关闭的数据帧,9表示 ping 数据帧,10表示 pong 数据帧,其余值暂时没有定义。ping 和 pong 用于心跳检测
- masked:表示是否进行掩码处理,长度为1.客户端发送给服务器端时为1,服务器端发送给客户端为0
- payload length:一个7、 7+16 或 7+64 位长的数据位,标识数据的长度。如果值在 0~125 间,那么该值就是数据的真实长度;如果值是126,则后面16位的值是数据的真实长度;如果值是127,那么后面64位的值是数据的真实长度
- masking key:当 masked 为1时存在,是一个32位长的数据位,用于解密数据
- payload data:模板数据,位数为8的倍数
网络服务与安全
Node 在网络安全上提供了 crypto、 tls、 https 三个模块
TLS/SSL
TLS/SSL 是一个公钥/密钥的结构,它是一个非对称的结构。公钥和密钥配对的,在建立安全传输前,客户端和服务器之间需要互换密钥。客户端发送服务器数据时要通过服务器端的公钥加密,服务器端发送数据时要通过客户端的公钥加密
为了解决中间人攻击问题,引入了数字证书进行认证,即 CA(Certificate Authority 数字证书认证中心)。CA 的作用是为站点颁发证书,且这个证书具有 CA 通过自己的公钥和密钥实现的签名
TLS 服务与普通的 TCP 服务仅仅只在证书的配置上有差别,其余部分基本相同
HTTPS
HTTPS 服务就是工作在 TLS/SSL 上的 HTTP。同样比 HTTP 服务多了证书的配置,其余部分基本相同
构建 Web 应用
请求方法
在 RESTful 类 Web 服务中请求方法十分重要,因为它决定资源的操作行为。PUT 表示新建一个资源,POST 表示更新一个资源,GET 表示查看一个资源,DELETE 表示删除一个资源
路径解析
常见的根据路径进行业务处理的应用是静态文件服务器,它会根据路径去查找磁盘中的文件,然后响应给客户端;另一种常见的分发场景是根据路径来选择控制器,它预设路径为控制器和行为的组合,无需额外配置路由信息
查询字符串
Node 提供 url 和 querystring 两个模块处理 url 及 url 的查询串。通常情况下,不需要直接处理querystring,因为url模块的支持
|
如果查询字符串中的键出现多次,那么它的值会是一个数组
Cookie
|
- path:表示这个 Cookie 影响到的路径,当前访问路径不满足该匹配时,浏览器不发送这个 Cookie
- Expires 和 Max-Age 用来告知浏览器这个 Cookie 何时过期,如果不设置该选项,关闭浏览器将丢失 Cookie,否者浏览器会将 Cookie 内容写入磁盘保存,下次打开浏览器依然有效。Expires 的值是一个 UTC 格式的时间字符串,告知浏览器 Cookie 几时过期,Max-Age 告知 Cookie 多久之后过期
- HttpOnly 告知浏览器不允许通过脚本 document.cookie 去改变 Cookie 值
- Secure 为 true 时在 HTTP 中无效,在 HTTPS 中表示创建的 Cookie 只能在 HTTPS 连接中被浏览器传递到服务器端进行会话验证
Cookie 的性能影响
Cookie 设置过多将导致报头较大,且大多数 Cookie 不是必须的
减小 Cookie 大小
如果在域名的根节点设置 Cookie,几乎所有的子路径的请求都会带上这些 Cookie。而静态文件的业务定位几乎不关心状态,Cookie 是多余的为静态组件使用不同的域名
为不需要 Cookie 的组件更换域名可以实现减少无效的 Cookie 的传输。换用域名同时可以突破浏览器下载线程数量的限制。但是换用域名会存在 DNS 查询的耗时问题减少 DNS 查询
限制通过多个域名加载资源。当今浏览器会进行 DNS 缓存,削弱了这个副作用的影响
Session
通过 Session 实现状态记录的几种方法
基于 Cookie 实现用户和数据的映射
Session 的数据只保留在服务器,并约定一个键值作为 Session 的口令保存在 Cookie。每次请求到来时,检查 Cookie 中的口令和服务器端的数据,如果过期,则重新生成通过查询字符串实现浏览器端和服务器端数据的对应
原理是检查请求的查询字符串,如果没有该值,则生成新的带值得字符串,做 302 跳转通过 HTTP 请求头的 ETag 实现数据映射
Session 与内存
一方面,Node 存在内存限制,将 Session 的数据存放在内存中在用户增多的情况下存在隐患,将引起垃圾回收的频繁扫描,引起性能问题;另一方面,如果利用多核 CPU 启动多个进程,则用户请求的连接可能随意分配到各个进程中,Node 的进程间无法共享内存,则用户的 Session 可能引起错乱
针对上述问题,常用的方法是 Session 集中化,将原本可能分散在多个内存中的数据,统一转移到集中的数据存储中,常用的工具有 Redi Memcached 等
Session 与安全
由于口令存放在客户端,则可能被伪造并窃取服务器端的数据。可以将口令通过私钥加密进行签名,使得伪造的成本较高
缓存
YSlow 提到的关于缓存的规则
- 添加 Expires 或 Cache-Control 到报文头中
- 配置 ETags
- 让 Ajax 可缓存
| 报文头 | 值/示例 | 类型 | 作用 |
|---|---|---|---|
| Expires | UTC 字符串 | 响应 | 告诉浏览器在过期时间前可以使用副本 |
| Cache-Control | no-chche | 响应 | 告诉浏览器忽略资源的缓存副本,强制每次请求直接发送给服务器 |
| no-store | 响应 | 强制缓存在任何情况下不要保留副本 | |
| max-age=[秒] | 响应 | 执行缓存副本的有效时长,从请求时间开始到过期时间之间的秒数 | |
| public | 响应 | 任何途径的缓存者(本地缓存,代理服务器)可以无条件缓存该资源 | |
| private | 响应 | 只针对单个用户或实体(不同用户,窗口)缓存资源 | |
| Last-Modified | UTC 字符串 | 响应 | 告诉浏览器当前资源最后修改时间 |
| If-Modified-Since | UTC 字符串 | 请求 | 如果浏览器第一次请求时响应中 Last-Modified 非空,第二次请求会把该项的值发送给服务器 |
| ETags | 标识符 | 响应 | 告知浏览器当前资源在服务器的唯一标识符(生成规则由服务器决定) |
| 标识符 | 请求 | 果浏览器第一次请求时响应中 ETags 非空,第二次请求会把该项的值发送给服务器 |
有如下两种更新机制:
- 每次发布,路径中跟随 Web 应用的版本号,如:http://url.com/?v20120917
- 每次发布时,路径中跟随该文件内容的 hash 值,如:http://url.com/?hash=abcdxxx
Basic 认证
Basic 认证中,它会将用户和密码部分组合,然后进行 Base64 编码。响应头中的 WWW-Authenticate 字段告知浏览器采用怎样的认证和加密方式。当认证通过,服务器端响应200状态码之后,浏览器会保存用户和密码口令,在后续的请求中都携带上 Authorization 信息
数据上传
表单数据
默认的表单提交,请求头中的 Content-Type 字段值是 application/x-www-form-urlencoded 。由于它的报文体内容与查询字符串相同,因此可以使用 querystring 解析
|
JSON 文件
|
XML 文件
|
附件上传
指定表单属性 enctype 为 multipart/form-data,则其报文头如下
|
代表本次提交的内容是由多部分构成的,其中 boundary=AaBo3x 指定每部分内容的分界符,AaBo3x 是随机生成的字符串,报文体的内容将通过在它前面添加--分隔,报文结束时在它前后都加上--表示结束。Content-Length 表示报文长度,太长则在 keep-alive 的情况下浏览器保持等待请求,太短则报文被截断
可通过 formidable 模块处理文件。它基于流式处理解析报文,将接收到的文件写入到系统的临时文件夹中,并返回对应的路径
数据上传与安全
内存限制
- 限制上传内容的大小,一旦超过限制,停止接收数据,并响应 400 状态码。通过 Content-Length 或 Buffer 长度判断
- 通过流式解析,将数据流导向磁盘中,Node 只保留文件路径等小数据
CSRF
全称 Cross-Site Request Forgery,即跨站请求伪造。用户在伪造网站 domain_b 提交表单到被攻击的站点 domain_a,则浏览器会将 domain_a 的 Cookie 发送到服务器,尽管请求来自 domain_b解决方法可以是页面渲染一个随机值并随表单一起提交,并在后台校验随机值是否一致
路由解析
MVC
MVC 模型工作模式如下:
- 路由解析,根据 URL 寻找对应的控制器和行为
- 行为调用相关的模型,进行数据操作
- 数据操作结束后,调用视图和相关数据进行页面渲染,输出到客户端
手工映射
|
正则匹配
|
自然映射
已约定的形式实现路由,而无需维护路由的映射。将路径划分处理
|
自然映射这种路由方式在 PHP 的 MVC 框架 CodeIgniter 应用十分广泛。与手工映射相比,如果 URL 变动,它的文件也需要发生变动,手工映射只需要改变路由映射即可
RESTful
全程 Representational State Transfer,即表现层状态转化。符合 REST 规范的设计,我们称为 RESTful 设计。它的设计哲学主要将服务器端提供的内容实体看做一个资源,并表现在 URL 上。通过 URL 设计资源,请求方法定义资源的操作,通过 Accept 决定资源的表现形式
中间件
引入中间件来简化和隔离基础设施与业务逻辑之间的细节,让开啊这能够关注在业务的开发上,已达到提升开发效率的目的
|
异常处理
为 next 添加 err 参数,并捕获中间件直接抛出的同步异常
|
可以为进行异常处理的中间件提供四个参数,并与普通中间件区分开
|
中间件与性能
编写高效的中间件
即提升单个处理单元的处理速度,尽早调用 next() 执行后续逻辑- 使用高效的办法,必要时使用 jsperf.com 测试基准性能
- 缓存需要重复计算的结果(需要控制缓存用量)
- 避免不必要的计算,比如 HTTP 报文体的解析对 GET 方法无用
- 合理利用路由
托管静态文件的中间件,可以通过添加路由路径,在不匹配路径的时候不会涉及该中间件
|
|
页面渲染
内容响应
浏览器通过 Content-Type 决定采用不同的渲染方式,这些值简称 MIME。其全称是 Multipurpose Internet Mail Extensions,最早用于电子邮件,后来也应用到浏览器中。不同文件类型具有不同的 MIME 值
| 类选 | 值 |
|---|---|
| HTML | text/html |
| TXT | text/plain |
| JSON | application/json |
| XML | application/xml |
| PNG | image/png |
Content-Type 后还可以包含一些参数,如字符集
|
附件下载
Content-Disposition 字段影响的行为是客户端会根据它的值判断是应该将报文数据当做即时浏览的内容,还是可下载的附件。当内容只需即时浏览时,它的值为 inline;当数据可以存为附件时,它的值为 attachment。另外,可以通过参数指定保存时应该使用的文件名
|
响应跳转
|
视图渲染
模板包括以下四个要素
- 模板语言
- 包含模板语言的模板文件
- 拥有动态数据的数据对象
- 模板引擎
其中,模板引擎氛围以下几个步骤
- 语法分解。提取出普通字符串和表达式,这个过程通常由正则表达式匹配
- 处理表达式。将标签表达式转换为普通的语言表达式
- 生成待执行的语句
- 与数据一起执行,生成最终字符串
Bigpipe
允许将页面分割为多个部分,先向用户输出没有数据的布局(框架),将每个部分逐步输出到前端,再最终渲染填充框架,完成整个页面的渲染
这是一个需要前后端配合实现的优化技术,有几个重要的点
- 页面布局框架(无数据)
- 后端持续性的数据输出
- 前端渲染
页面布局
|
持续数据输出
|
前端渲染
bigpipe.ready() 和 bigpipe.set() 是整个前端的渲染机智。前者注册一个事件,后者触发一个事件
Bigpipe 将页面布局和数据渲染分离,随着数据输出的过程逐步渲染页面。通过 Ajax 也能完成,但 Ajax 背后是 HTTP 调用,消耗更多的网络连接
玩转进程
多进程架构
创建子进程
child_process 模块提供创建子进程的方法
- spawn():启动一个子进程来执行命令
- exec():启动一个子进程来执行命令,与 spawn() 不同的是它有一个回调函数获知子进程的状况
- execFile():启动一个子进程来执行可执行文件
- fork():与 spawn() 类似,不同点在于它创建 Node 的子进程只需指定要执行的 Javascript 文件模块即可
执行 work.js 的示例如下
|
创建子进程之后将返回子进程对象,差别如下:
| 类型 | 回调/异常 | 进程类型 | 执行类型 | 可设置超时 |
|---|---|---|---|---|
| spawn() | 否 | 任意 | 命令 | 否 |
| exec() | 是 | 任意 | 命令 | 是 |
| execFile() | 是 | 任意 | 可执行文件 | 是 |
| fork() | 否 | Node | Javascript 文件 | 否 |
如果希望通过 execFile 执行 Javascript 文件,则需要在首行添加如下代码
|
进程间通信
浏览器中,Javascript 主线程与 UI 渲染共用同一个线程,执行 Javascript 和渲染 UI 两者互相阻塞。HTML5 提出了 WebWorker API,允许创建工作线程在后台运行。在 Node 中主线程与工作线程之间的通信与 worker 类似
|
父进程与子进程通过 UPC 通道传递消息。IPC 全程是 InterProcess Communication,即进程间通信。父进程在实际创建子进程钱,会创建 IPC 通道并监听它,然后创建出子进程,告知子进程 IPC 通道的文件描述符,子进程在启动过程中通过文件描述符去连接已存在的 IPC 通道,从而完成父子进程间的连接
句柄传递
句柄指一种可以用来标识资源的引用,其内部包含了指向对象的文件描述符。Node 允许进程间发送句柄
|
在发送完句柄并关闭监听之后,多个子进程可以同时监听相同端口而不会抛出异常,理由在于向子进程发送句柄后,多个子进程可以拿到相同 TCP 服务器端 socket 套接字的文件描述符,因此能够同时监听相同端口不会引起异常。而文件描述符同一时间只能被某个进程引用,也就是说一个请求只能被一个进程处理,切这种进程服务是抢占式的
此外,发送句柄尽管看起来像是把 server 对象发送给子进程,实际上只传递了我们要发送的句柄文件描述符。Node 进程间只有消息传递,不会传递真正的对象,发送句柄的使用是抽象封装的结果
目前子进程对象 send() 方法允许发送的句柄类型如下几种
- net.Socket:TCP 套接字
- net.Server:Tcp 服务器
- net.Native:C++ 层面的 TCP 套接字 或 IPC 通道
- dgram.Socket:UDP 套接字
- dgram.Native:C++ 层面的 UDP 套接字
集群
进程事件
子进程对象除了 send() 方法和 message 事件歪,还有如下事件
- error:当子进程无法被复制创建、无法被杀死、无法发送消息时触发
- exit:子进程退出时触发该事件。子进程如果正常退出,则第一个参数为退出码,否则为 null。如果子进程是通过 kill() 方法杀死,则得到第二个参数,表示杀死进程时的信号
- close:在子进程的标准输入输出流终止时触发该事件,参数与 exit 相同
- disconnect:在父进程或子进程中调用 disconnect() 方法时触发,调用该方法将关闭监听 IPC 通道
kill:允许父进程向子进程发送系统信号杀掉子进程,或者子进程自杀
child.kill([signal]);process.kill(pid, [signal]);
关于 kill 信号,常用有如下几个
| 名称 | 编号 | 类型 |
|---|---|---|
| HUP | 1 | 终端断线 |
| INT | 2 | 中断(同 Ctrl + C) |
| QUIT | 3 | 退出(同 Ctrl + \) |
| TERM | 5 | 终止 |
| KILL | 9 | 强制终止 |
| CONT | 8 | 继续(与STOP相反, fg/bg命令) |
| STOP | 9 | 暂停(同 Ctrl + Z) |
自动重启
父进程创建子进程时,子进程监听 exit 事件,在退出时触发创建新的子进程即可
然而上述存在的问题是,子进程只有在断开所有连接之后才会退出。因此可以调整为子进程在抛出未捕获异常时,向父进程发送自杀消息,父进程便可以在子进程退出之前创建新的子进程
如果多次出现未捕获异常,有必要收集异常日志并发出警报。也可以添加计数器,检查是否频繁重启,有利于及时发现问题所在
负载均衡
在多进程之间监听相同的端口,使得用户请求能够分散到多个进程上进行处理,而保证多个处理单元工作量公平的策略叫做负载均衡。Node 默认提供的机制是采用操作系统的抢占式策略
然而 Node 的繁忙需要分清 CPU 和 I/O,可能造成负衡不均匀的情况
为此 Node 在 v0.11 中提供了一种新的侧咧 Round-Robin,又叫伦叫调度。由主进程接受连接,将其一次分发给工作进程。在 cluster 模块中启用它的方式是
|
状态共享
由于 Node 进程间无法共享数据,所以是欧诺个第三方来进行数据存储是最简单直接的方式
实现状态同步的机制有两种,一种是各个子进程去向第三方进行定时轮询,带来的问题显而易见;另一种是主动通知,即当数据发生更新时,主动通知子进程,这个过程仍然不能脱轮询,但可以减少轮询的进程数量,我们将这种用来发送通知和查询状态是否更改的进程叫通知进程
Clustor 模块
v0.8 引入了 cluster 模块用于解决多核 cpu 的利用率问题,同时提供了完善的 API,用以处理进程的健壮性
|
可以通过环境变量中是否有 NODE_UNIQUE_ID 判断是主进程还是工作进程
|
工作原理
cluster 模块是 child_process 和 net 模块的组合应用,其内部创建 TCP 服务器的方式对使用者来说十分透明,但也由此使得一个进程只能管理一组工作进程,无法向 child_process 那么灵活
Cluster 事件
- fork:复制一个工作进程后触发该事件
- online:复制好一个工作进程后,工作进程主动发送一条 online 消息给主线程,主线程收到消息后触发该事件
- listening:工作进程中调用 listen()(共享了服务器端 socket)后,发送一条 listening 消息给主进程,主进程收到消息后触发该事件
- disconnect:主进程和工作进程之间 IPC 通道断开后会触发该事件
- exit:有工作进程退出时触发该事件
- setup:cluster.setMaster() 执行后触发该事件
测试
单元测试介绍
断言
Javascript 的断言规范最早来自于 CommonJS 的单元测试,Node 实现了规范中的断言部分
|
断言规范中定义了以下几种检测方法
- ok():判断结果是否为真
- equal():判断实际值与期望值是否相同
- notEqual():判断实际值与期望值是否不相同
- deepEqual():判断实际值与期望值是否深度相同(对象或数组的元素是否相等)
- notDeepEqual():判断实际值与期望值是否不深度相等
- strictEqual():判断实际值与期望值是否严格相等(相当于 ===)
- notStrictEqual():判断实际值与期望值是否不严格相等(相当于 !==)
- throws():判断代码块是否抛出异常
除此之外,Node 的 assect 模块还扩展了如下两个断言方法
- doesNotThrow():判断代码块是否没有抛出异常
- ifError():判断实际值是否为一个假值(null、 undefined、 0、 ‘’、 false),如果实际值为真值,则抛出异常
测试框架
测试框架能记录下抛出的异常并继续执行,最后生成测试报告。其为用于为测试服务,本身不参与测试。这里介绍 mocha
陷阱流星的单元测试风格主要由 TDD(测试驱动开始)和 BDD(行为驱动开发)两种(wiki 显示其属于开发方法)。前者从功能的角度上设计测试用例,主要由开发人员引导;后者从自然行为的角度设计测试用例,鼓励非研发人员参与
mocha 支持上述两种风格,提供不同的关键字
mocha 提供不同的测试报告格式,通过mocha --reporters可查看所有支持的格式。可将结果传递给其他程序处理,而html-cov可用于可视化观察代码覆盖率
简单的 TDD 风格的测试用例如下
|
异步测试
通过参数长度判断是否异步测试
BDD 风格的异步测试用例
|
超时设置
可以在测试用例it中通过 this.timeout(s) 实现对单个用例的特殊设置,也可以在描述 describe 中调用 this.timeout(s) 设置描述下当前层级的所有用例
测试覆盖率
可以通过 jscover 或者 blanket 模块报告测试覆盖率,前者通过 Java 实现,编译之后在每行代码前插入统计代码再执行,后者由 js 实现,原理与前者相同。这里介绍 blanket
使用 blanket 报告代码覆盖率需要在所有测试用例运行之前通过 –require 选项引入它既可
|
另外,需要在包描述文件中配置 scripts 节点。在 scripts 节点中,pattern 属性用以匹配需要编译的文件
|
mock
模拟异常较难实现,称为 mock。看可以通过伪造被调用方来测试上层代码的健壮性
|
相当于猴子补丁,也可以通过 muk 模块帮忙
同时,对于异步方法的模拟,需要小心是否将异步方法模拟为同步。通过 process.nextTick() 辅助即可
私有方法的测试
除了 exports 导出的属性和方法,其他私有方法难以测试。可通过 rewire 实现对私有方法的测试
工程化与自动化
通过 Makefile 完成自动化编译,通过 travis-ci 解决持续集成
性能测试
基准测试要统计在多少时间内执行了多少次某个方法。为了增强可比性,一般会以次数作为参照物,然后比较时间,以此判别性能的差距
压力测试
|
基准测试驱动开发
- 写基准测试
- 写/改代码
- 收集数据
- 找出问题
- 回到第 2 步
测试数据与业务数据的转换
根据实际业务评估业务量,计算公式为
|
产品化
项目工程化
构建工具
- Makefile:*nix 系统下经典的构建工具。依托强大的 bash 编程,通常用来管理一些编译相关的工作
- Grunt:依托丰富的插件,自身提供通用接口用于插件的接入,具体的任务由插件完成
编码规范
通过文档式的约定和代码提交时的强制检查实现
代码审查
主要在请求合并的过程中完成,需要审查功能是否正确完成、编码风格是否符合规范、单元测试是否同步添加
部署流程
部署操作中,可能会用到 nohup 和 & 以不挂断的方式让进程持续执行
|
停止和重启进程则比启动进程复杂一点,可通过 bash 脚本实现。主进程在启动时将进程 ID 写入一个 pid 文件,以此通过脚本管理进程
性能
- 动静分离
将动态请求和静态请求分离后,服务器可以专注动态服务方面,CDN 托管静态文件能够有更精确和高效的缓存机制,而且不同域名能消除不必要的 Cookie 传输和浏览器对下载线程数的限制 - 启用缓存
- 多进程架构
- 读写分离
日志
访问日志
一般用来记录每个客户端所对应的访问。在 Web 应用中,主要记录 HTTP 请求中的关键数据异常日志
通常用来记录那些意外产生的异常错误。通过日志的记录,能够较快地定位问题所在。console 对象上具有一个 Console 属性,是 console 对象的构造函数。借助这个构造函数,可以实现自己的日志对象。代码如下:var info = fs.createWriteStream(logdir + '/info.log', {flags: 'a', mode: '0666'});var error = fs.createWriteStream(logdir + '/error.log', {flags: 'a', mode: '0666'});var logger = new console.Console(info, error);// 使用logger.log('hello');logger.errer('fault');异常处理
开发者应该当将 API 内部发生的异常座位第一个实参传递给回调函数。对于回调函数中产生的异常,则交给全局的 uncaughtException 事件去捕获即可在逐层次的异步 API 调用中,建议将异常交给最上层的调用者捕获记录,底层调用或中间层调用中出现的异常只要正常传递给上方德调用方即可
日志与数据库
日志文件与数据库写入在性能上处于两个级别,数据库在写入过程中药经历一系列处理,比如锁表、日志等操作;写日志文件则是将数据直接写到磁盘上。如果有大量访问,可能存在写入操作大量排队的问题,数据库的消费速度严重低于生产速度,进而导致内存泄露
监控报警
- 日志监控
- 响应时间
- 进程监控
- 磁盘监控
- 内存监控
- CPU 占用监控
- CPU load 监控
- I/O 监控
- 网络监控
- 应用状态监控
- DNS 监控
稳定性
- 多机器
- 多机房
- 容灾备份
异构共存
在应用 Node 的过程中,不存在为了用它而推翻已有设计的情况。Node 能够通过协议与已有的系统很好地异构共存