基于 Tesseract 和 GM 识别验证码
之前爬代理 IP 的时候发现一些网站把端口号用验证码的形式显示,于是花了一个下午的时间瞄了一些识别验证码的东西,并用 Node.js 包装了一下,暂时叫 verify 好了
依赖环境
这里主要用到两个工具,分别是 Tesseract 和 GraphicsMagick。前者是开源的 OCR (Optical Character Recognition, 光学字符识别) 工具,目前由谷歌维护;后者是是图像处理的瑞士军刀。macOS 下推荐使用 Homebrew 安装,这样会省去很多安装依赖库之类的麻烦。
|
通过 Homebrew 安装 GM 和 Tesseract,安装 GM 出现问题可以参考 这里
|
|
Tesseract 中参数 --with-training-tools 表示同时安装训练识别库的工具,不需要可以忽略;默认安装会带有英文字符的识别库,文件夹路径为 /usr/local/share/tessdata,也可以添加参数 --all-languages 下载官方提供的各个语言的识别库,不过体积较大推荐手动下载。如果需要手动指定识别库的路径可以添加环境变量然后重启终端。
|
除了依赖环境,Node.js 还需要安装前面两个工具对应 Node.js 的封装模块 node-tesseract 和 gm。
识别验证码
一般情况下,为了防止验证码简单地被识别,一般会在验证码背景加上干扰的线条或噪点。类似的做法会使得 tesseract-ocr 的识别成功率极大地降低。因此在识别图像之前,需要通过 GM 对图片进行处理以降低干扰。
简单粗暴的处理方法是调整图片的阈值。在 PhotoShop 里面,“阈值”命令将灰色或彩色图像转换为高对比度的黑白图像。可以指定某个色阶作为阈值。所有比阈值亮的像素转换为白色;而所有比阈值暗的像素转换为黑色。
以下图为例,是将验证码的阈值调整为 55(22%) 的结果,也可以手动在 PhotoShop 尝试调整阈值并预览。
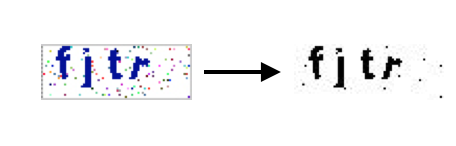
基于 GM 处理阈值的实现如下:
|
得到优化过的图片之后,就可以将输出的图片路径交给 Tesseract 进行识别了,代码也比较简单:
|
到这里已经完成了识别验证码的所有工作了~
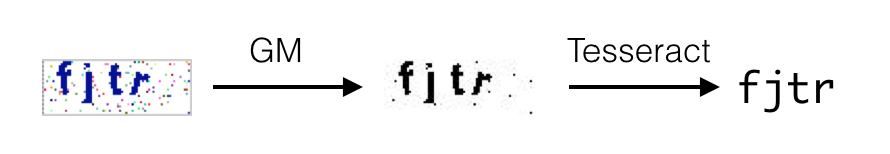
问题
实际上,处理验证码的过程不会这么顺利。有下面几个问题:
- GM 调整阈值如果直接使用数值会导致输出的图片空白
- 图片的透明通道会被 GM 干掉变成黑色
- 由于 Tesseract 中
Leptonica模块在 OSX 上存在问题导致无法识别 .gif 图片 - Tesseract 默认配置下的识别准确度不足,经常遇到识别错误的情况
第 1 个问题通过阈值的百分比绕过,第 2 个问题通过 GM 的 -flattern 解决,第 3 个问题只要把提供识别的图片转换为 .jpg 格式就行了。修改后:
|
第 4 个问题可以通过训练样本提高识别准确度,有点繁琐但也好上手,具体可参考:
其他
GM 的官方文档已经比较完善了,然后在 node-tesseract 使用过程中发现接触到的可配置参数主要有这几个:
l: 指定训练生成的语言包,默认为engpsm: 识别模式,常用的为psm: 7,即单行文本config: 可配置项,比如config: ['digits']会指定为只识别数字